짝지은
자료의 분석은
기본적으로 3가지
통계법을 사용합니다.
Paired t-test 삼총사, McNemar test, Wilcoxon t-test
(알고보면 더
많지만 일단은….)
이른바 “Paired t-test 삼총사”입니다. 누가 이렇게 말했느냐?
제가 말했기 때문에 딴데가서 이런 식으로 말하면 안되고,
그냥 느낌으로만 알고 있어야 할 단어입니다.
당연히 Paired t-test 가 포함되고, 더불어 McNemar test와 Wilcoxon t-test가 있습니다.

예를
들어 보죠.
홍길동이
나이가 들어서 관절염이 생겼고,
각각 오른쪽 다리 왼쪽 다리에 다른 치료법을
사용하였습니다.
그래서 그
결과를 이런 식으로 표현하였습니다.
한편
성공하기도 하고, 실패하기도
했는데,
여러
사람에게서 이런 결과를 얻었습니다.
이 둘
중에서 어떤 치료법이 좋은지 알아 보려고 합니다.

동일한
결과를 이렇게 길게 세로로 길게 표현할 수도 있습니다.
사람이
아주 많다면, 또 treat_A를 하고 나서 1년쯤 지나서 treat_B를 한다면,
위의
폼처럼 만들려면
다시
홍길동을 찾아야 하지만,
아래
표처럼 그냥 한줄로 기록한 다음 나중에
바꾸는
것이 더 편할 수도 있을 것입니다.
위의
양식을 wide
form이라고 하고,
아래
양식을 long
form이라고 합니다.
아니, 위의 것이 더 wide 하지
않습니다.
라고
말씀하시는 분도 있겠죠.

그런데, 조금 더 확장해서, 치료 방법이 더 누적되어 3개, 4개..
이런
식으로 결과가 있다면,
그
이름의 의미가 더욱 명확해 집니다.
즉,
wide form은 더
wider 해 지고,
Long
form은 더 longer 해
집니다.
일단은
우리는 다시 가장 단순한 구조로 살펴 보겠습니다.

그런데
간혹 이런 경우가 있는데,
홍길동의
쌍둥이(형제)가 있어서, 쌍둥이(형제)간에
treat_A 혹은 treat_B 이런
식으로
다른
치료를 하는 연구를 할 수도 있겠지요.
이런 식의
연구는 홍길동의 쌍둥이이기 때문에
많은
조건들이 일치하므로, 짝지어진
자료라고
부릅니다.
많은
조건들이 일치하지만, 똑같지는
않죠.
이런
경우에는 wide form은
좀 표현하기 어렵습니다.
홍길동에게도
나이, 체중, 키 등등
기록할 것들이 많이 있고,
홍길동2에게도
역시 기록할 것이 많아서,
Long
form이
더 적격합니다.
만일
홍길동 쌍둥이가 아니라,
홍길동
형제라면 어떨까요?
형제간
연구도 마찬가지로 long form이
더 입력하기가 편리하고
부부간
연구도 그렇습니다.
그런데 (간단한) 통계를
돌리기에는 wide form이
더 편하고
이해하기도
편합니다.
어쨌든 두
가지 모두 익숙해지면 좋고,
나중에는
상화 변형을 쉽게 할 수 있도록
하는 것이
좋습니다.

자 이제 가장
간단한 형태로 이렇게 자료가 모아 졌다고 합시다.
양 다리의
수술 결과라고 할 수도 있고,
쌍둥이 또는
형제의 결과라고 할 수도 있습니다.
아 그리고, treat 대신에
condition이라고
넣어도 됩니다.

제가
만들어 둔 엑셀 파일에 이렇게 넣어 보겠습니다.
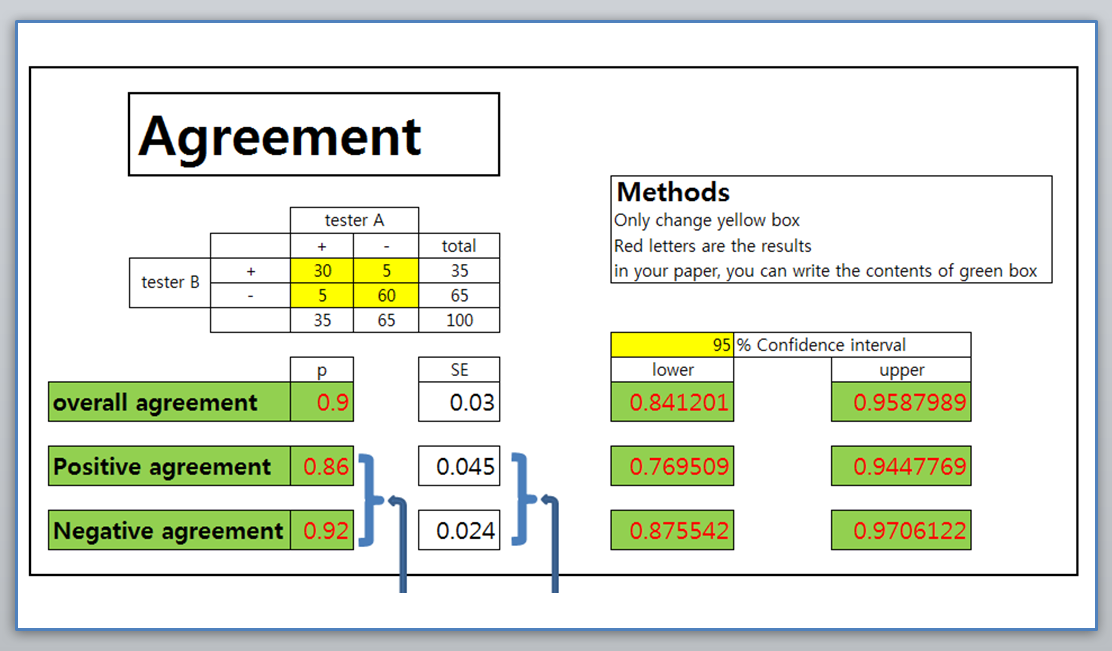
(1)의
노란색 칸에 결과를 넣으면,
(2)표에 연두색 칸에 그대로 옮겨지고, 그 아래에
오즈비(OR)와, 위험차(RD) 및 p값이 구해지게 됩니다.
결과적으로
p>0.05이며 유의하지 않은 결과이군요.
보통, (2)와 같은 2x2
table로
표현하는 경우가 많은데,
저는
그것보다는 세로로 된 (1)의
표로 표현하는 것을 권장합니다.
왜냐하면
카이제곱 검정에서 쓰인 2x2와
혼동될 수 있어서 입니다.

참고로
이건 위키피디아에서 나온 McNemar
test의 예입니다.
NEJM의
예에서 잘못된 예를 보여줍니다.
즉,
Hodgkin 병과 tonsillectomy의
연관성을 보여주는데,
형제에
대해서 검정한 것입니다.
무엇이
잘못되었냐 하면,
병에 걸린
사람과 걸리지 않은 사람이 독립된 것이 아니라,
형제 간에
연구한 것이기 때문에, 카이제곱
검정을 하면 안되고,
McNemar
test를
해야한다는
것이 주장입니다.
이것은 John Rice라는
분이 쓴 책에 나온 것을
위키피디아에서
인용한 것이고요,
이 예는 McNemar test 강의
때에 다른 사람들도
자주
인용하는 것같습니다.