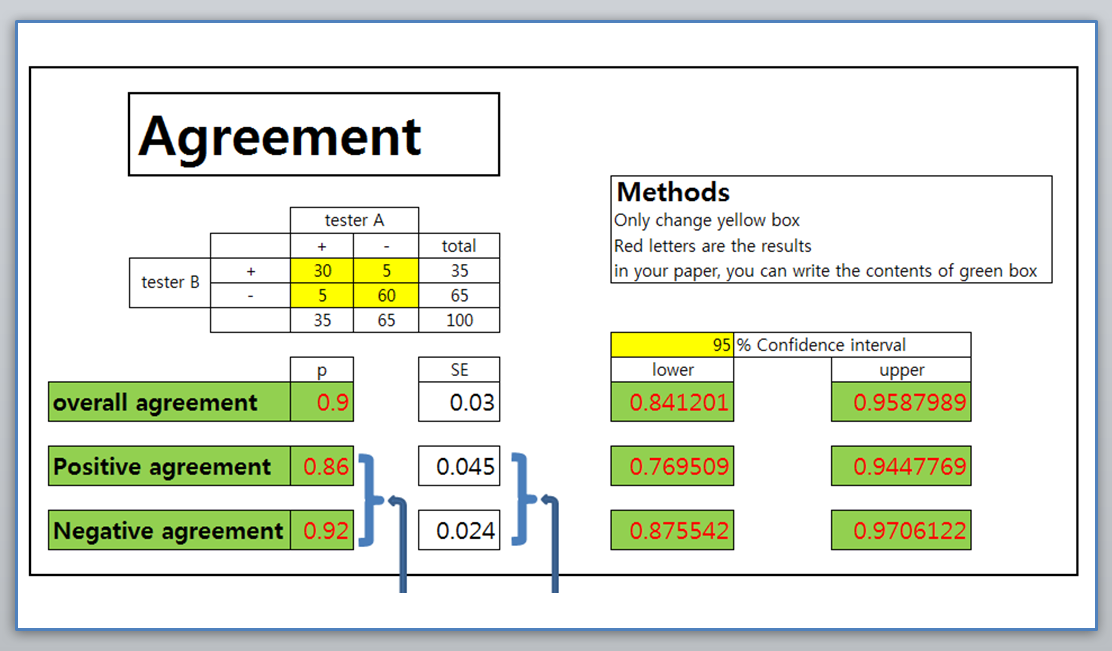
빅데이터로 분석한
한 예를 찾아 보겠습니다.

이
논문이고요,
2011년 JAMA에 나온 것입니다.
이
정도면 쟁쟁하죠.
5대
심혈관질환의 위험인자인
hypertension, smoking, dyslipidemia,
diabetes,
그리고
family
history of coronary heart disease
의
유무를 분석했고
542,008명의 최초 심근 경색이 발생한 환자에서,
재발생에 대해 연구했습니다.
National Registry of Myocardial
Infarction, 1994-2006.
국가
등록에서 조사한 것입니다.
•Center
for Cardiovascular Prevention, Research and Education, Watson Clinic LLP,
Lakeland, Florida
;
•University
of
Massachusetts Medical School, Worcester ;
•University
of Alabama
Medical Center, Birmingham ;
•Duke Clinical
Research Institute, Duke University
Medical
Center, Durham, North Carolina ;
•ICON Late
Phase & Outcomes Research, San
Francisco, California ;
•Harbor-UCLA
Medical
Center, Torrance, California
;
•Beth Israel
Deaconess Medical Center, Harvard Medical School, Boston, Massachusetts
;
•University
of
Pennsylvania, Philadelphia ;
•Virginia
Commonwealth University,
Richmond ; Wayne
State University School of Medicine, Detroit, Michigan ;
•Mid Michigan
Health, Midland ;
•Washington
University School
of Medicine, St Louis, Missouri Northwestern University,
Clinical
and
Translational Sciences Institute, Chicago, Illinois .
정말
쟁쟁한 병원의 연구진들이 이 연구에 참여하였습니다.

그런데, 주된 결과인 이것,
Figure 2입니다.
Fisk factor가 적을수록(위의 것들)
더
사망률이 높다는 것.
이게
왠일입니까?

그림 2 아래 있는 설명입니다.
엄청
많은 변수들을 넣었습니다.

논문의 결론입니다.
그림에서 보다시피,
위험인자가 많을수록 병원에서 사망률이 적어진다는 것.
왜 그럴까요?
우리가 측정하지 못한 교란변수일까요?
그런데 저자들은 여러 교란변수에 대해서 extensive
adjust를 했다고 했고
Subgroup에 대해서도 분석했습니다.
이 결론에 대해서 우리는 무엇을 생각할 수 있을까요?
병원외 사망률
아주
위험한 사망의 경우에는 병원에 오기 전에 이미 사망하지 않을까요?
그렇다면, 이 국가 자료 자체의 문제가 있는 셈이군요.
제대로 조사가 안된 거니까요.
혹시
위험인자가 많은 사람은…
더 심근 경색이 오지 않도록 조심하는 것은 아닐까요?
갑자기
추운 것에 노출하지 않고,
항상 마음을 안정화 시키려고 노력하고,
또
병원 가까이에 살면서 응급조치할 준비를 하거나
응급약을 항상 준비하고 다니는 것은 아닐까요?
그런
것에 대한 변수는 미리 측정하지 않은 것같은데요….
=======================
어쨌든
저는 이런 생각을 떨칠 수가 없습니다.
만일
이 연구의 결과가 우리의 예상과 상식에 맞게 나왔다면?
그러면
사실 이런 연구를 할 필요가 없죠.
상식에
맞게 나왔으니까 별다른게 없이 인정되는 거죠.
그리고, 그것을 그냥 받아들이겠죠.
만일
이렇게 우리의 상식과 다른 결과가 나왔을 때
이건
우리가 미쳐 고려하지 않은 다른 변수가 있을꺼야.
그리고, 다시 다른 변수를 넣어서 시행하기를 반복합니다.
그리고선
결국
우리의
상식에 맞는 결론이 나오면 연구를 멈춘다면…….
그러면
그건 조작이 아닐까요?
지금
내가 얻은 결과가 과연 믿을 수 있다고 어떻게 확신하죠.
미쳐
고려치 못한 다른 변수가 있다면 말이죠…….
그리고, 다시 생각해 보면,
빅데이터라고 하면 문제가 해결될까요?
그것이
잘못된 원래부터 잘못 측정된 데이터라면
어떻게
할까요?
개가
사람을 물면 기사에 나올까요?
가끔 나겠죠.
사람이
개를 물면 구글에 대번 퍼지고,
페이스북에서 공유될 것입니다.
그러면
그것을 분석하는 제 삼자는
이렇게
분석할지도 모릅니다.
“사람이
개를 무는 회수는 개가 사람을 무는 회수의 4,8배 p<0.001”
“인종, 지역, 계절, 시간적 변수를 adjust
했음”
이렇게
말이죠.
어떻게
생각하시나요?
최소한 100년쯤 지난 뒤 오늘의 인터넷에
나온 글을 분석하는 사람은 그런 결론을 내릴지도 모르죠.
또 지금 신문과 뉴스에서 발표되고,
바로 다음날 전국민적인 식생활에
영향을 주는 그런 연구들은
JAMA보다도 훨씬 검증안된
그런 저널에 실린 것도 많은데,
그건 어떻게 믿을 수 있죠?
----------------------------
많은
시사점을 주는 글이라고 생각됩니다.
위
논문은 pubmed에서 무료로 전문을 볼 수 있습니다.